Testing & Evaluation Articles
35 articles · Page 3 of 3
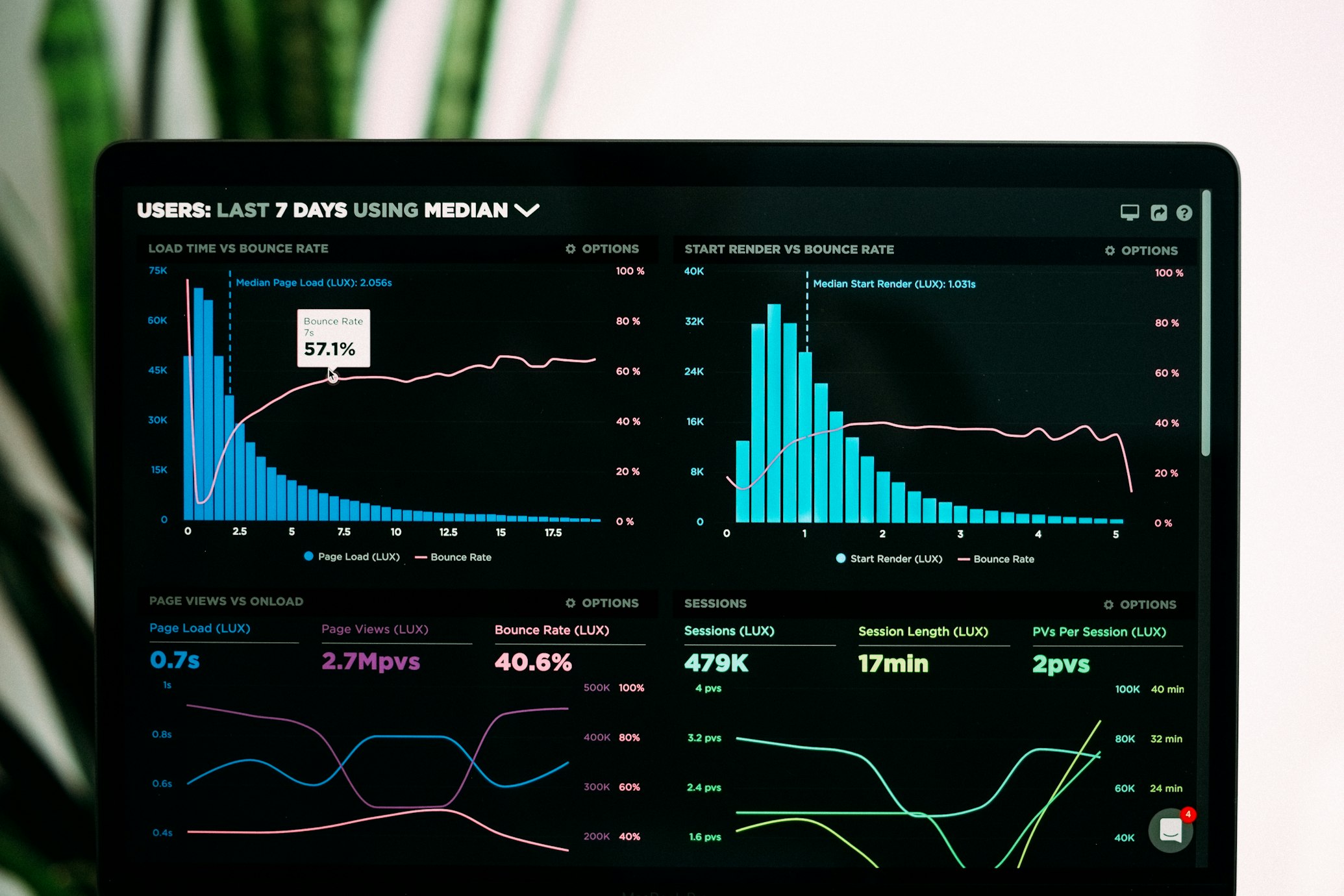
Is Your AI Agent Actually Ready for Production? The 3 Tests Most Teams Skip
Most AI agent failures happen not because the agent is bad, but because it was never properly tested. Here's the testing framework (unit, A/B, and live) that catches what demos miss.

AI Agent Testing: How to Evaluate Agents Before They Talk to Customers
A practical guide to testing AI agents before production — scenario-based testing with AI personas, scorecard evaluation, regression suites, edge case generation, and CI/CD integration.

Who's Testing Your AI Agent Before It Talks to Customers?
Traditional QA validates deterministic code. AI agent QA must validate probabilistic conversations. Here's why that gap is breaking production deployments.

Scenario Testing: The QA Strategy That Catches What Unit Tests Miss
Discover how synthetic test conversations catch edge cases that unit tests miss. Personas, adversarial scenarios, and regression testing for AI agents.

Scorecards vs. Vibes: How to Actually Measure AI Agent Quality
Most teams 'feel' their AI agent is good. Here's how to build structured scoring with rubrics, automated grading, and regression detection that holds up.

Voice AI Tests Pass in the Lab. They Fail on the Call.
Why happy-path test suites pass voice agents through QA that fall apart on the first real call, and the five testing habits that actually catch the failures.

Automated QA Grading: Are AI Models Better Call Scorers Than Humans?
Industry research shows that 75-80% of enterprises are implementing AI-powered QA grading systems. Discover whether AI models actually outperform human call scorers and how to implement effective automated grading.
Performance Benchmarks for AI Agents: What Actually Matters Beyond Word Error Rate
Most enterprises obsess over Word Error Rate while missing the metrics that actually predict success. Here's what to measure instead.

Testing Bias: How to Measure and Reduce Socio-linguistic Disparities in AI
A practical guide to detecting and measuring bias in AI voice and chat agents. Covers specific metrics, testing approaches, scorecard design, and what teams actually do when they find disparities.

The Voice AI Quality Crisis: Why Most Deployments Fail in Production
Most voice AI deployments fail in production despite passing lab tests. Real data on why the gap exists, what it costs, and how to close it.

The 12 Critical Edge Cases That Break Voice AI Agents
Uncover the most common edge cases that cause voice AI failures and learn how to test for them systematically to prevent customer frustration.
The Signal Briefing
Un email por semana. Cómo los equipos líderes de CS, ingresos e IA están convirtiendo conversaciones en decisiones. Benchmarks, playbooks y lo que funciona en producción.